Explainable AI: The What’s and Why’s
Part 1: The What
Continued advances promise to produce autonomous systems that will perceive, learn, decide, and act on their own. However, the effectiveness of these systems is limited by the machine’s current inability to explain their decisions and actions to human users. — Dr. Matt Turek (DARPA)

There have been incredible advancements in AI/ML over the last decade with Large Language Models (LLM) such as BERT and GPT-3 as well as diffusion models like DALL·E 2 taking the center stage in the public arena. And while these foundational models, a term made popular by Stanford’s Human-Centered Artificial Intelligence center, are a giant leap forward in machine learning another important research area is being overshadowed in the technological zeitgeist. Explainability in artificial intelligence. But what is Explainable AI (XAI), and why is it important? In this series I’ll touch on what XAI is and why we need it more now than ever.
What is Explainable AI?

At the highest level, XAI is really just artificial intelligence where the results can be understood by humans. See…simple. You put data in one side and the model or system of models produces an output and tells you why it made that decision. But as with all things there’s more complexity than that. Not all AI/ML methods are made equal which creates a continuum of model explainability that’s largely based on the model architecture itself. I like to refer to the different levels of explainability as interpretable, less interpretable, and explainable.
Let’s start with one of the simplest approaches, linear regression. A decision made by a linear regression model is fairly easy to understand, particularly in a one variable example like in the figure below. The model is trying to draw a straight (linear) line that best fits within the data. It’s able to give you the coefficients of all the variables being used and you can easily look at these and directly see which has the most effect on the outcome and whether that effect is positive or negative. It is fully interpretable. But, just like it says on the tin, it only works with linear relationships in the data. What if we have a non-linear problem where a straight line won’t do the trick?

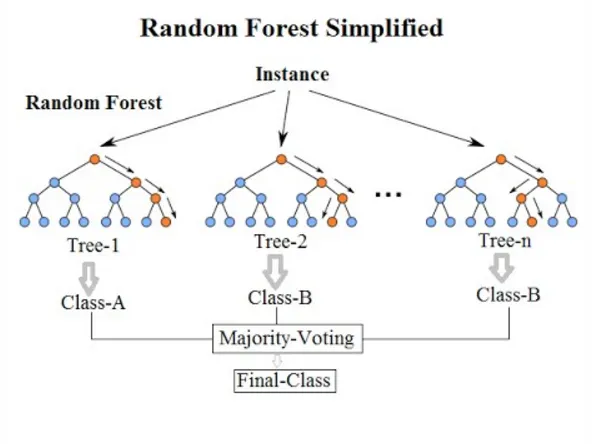
If that’s the case then we’re going to have to start looking at more complex models. For instance a random forest, which at its core is just a group of decision trees that are combined in an ensemble. It can deal with some non-linearity and it’s seemly still interpretable. Models like a random forest, or its big brother the gradient boosted random forest, still give you insight into why it made the decisions it did using metrics like Gini impurity to see variable importance. But try explaining entropy or information gain at your next family holiday and you’ll see why a more complex model like a random forest is less interpretable than linear regression. We can get a sense of which variables are important to the model’s decision making but it’s not as direct as the coefficients of a linear regression. Most of the problems we are trying to solve on a day to day basis can be solved with these less interpretable models, but more and more we are facing situations where something with more computational power is needed.
Enter Deep Learning and Neural Networks, the proverbial top of the pile for machine learning. Deep learning is the backbone to a lot of the recent advancements in AI/ML and are all over the news. The foundational models mentioned before are all, under the hood, versions and permutations of neural networks. I won’t go into the exact workings of neural nets but at their simplest make up they are just a system of interconnected nodes that take an input and use the weights of the internal (hidden) nodes and use activations to apply some calculations and eventually give you a predicted output. The output is tested against the actual outcome and the error is pushed backwards through the model (backpropagation) and all of the node weights are updated. These sorts of models are incredibly powerful, but tend to be referred to as “black box models” because there is no direct way to interpret how they’ve made a decision. There are ways to help understand the inner workings of a neural network, but we can’t directly see how a neural network is determining an output. They are explainable but not interpretable.

Three Stages of Explanation
All of the discussion above is centered on the model itself, but there are actually three stages where explainability comes into play: Pre-modeling Explainability, Explainable Modeling and Post-modeling Explainability.

Explainable AI really starts with explainable data. If you can’t understand the data going in then there’s no way to truly understand the prediction coming out. So first and foremost is doing exploratory data analysis to understand distributions, how variables are related, and the general interactions of different parts of the dataset. This will give you a sense of the general make up of the dataset and could potentially already be giving some insight into the variable to be predicted. Another key aspect to pre-modeling explainability is how feature engineering is done and making that as explainable as possible. Combining two variables together or creating a ratio is easily explained. But using Principal Component Analysis (PCA) to reduce the amount of variables in the data is going make it harder to explain the outcome because PCA itself is hard to decompose back to the original variables.
When it comes to the model itself the first rule of thumb is to use the most interpretable model while still getting good predictive results. But sometimes, like discussed above, a more complex model is needed. If that’s the case there are numerous ways to have an explainable model. In a later post I’ll discuss some of the ways to ADD explainability to a model, but for now just know that there are many options out there.
And finally, there’s post-model explainability. Again there are many ways to go about it but the main two are perturbation and Game-theoretic analysis. The first, perturbation, is when you change a value in the data and see how it affects the model outcome. What happens if we change a variable from A to B? If the model still performs well then that variable isn’t a key contributor. But on the other hand if the model accuracy is reduced then we know that the variable is important to the model’s prediction. Game-theoretic analysis is more complex, but essentially leads to the same result. This sort of analysis, using something like SHAP values, uses Game Theory to understand the contribution of each variable to the outcome. The mechanism for that is way beyond the scope of this article but in the end either perturbation or Game-theoretic analysis is going to do an excellent job of adding explainability to a model after it’s already been trained.
So hopefully now you have a better understanding of what XAI IS. In my next article I’ll go over WHY we need explainable AI and its impact on understanding bias in machine learning applications.